Reranking: The Key to Accurate Retrieval Augmented Generation (RAG) Systems
Nov 21, 2024 by Sabber ahamed
Reranking: The Key to Accurate Retrieval Augmented Generation (RAG) Systems
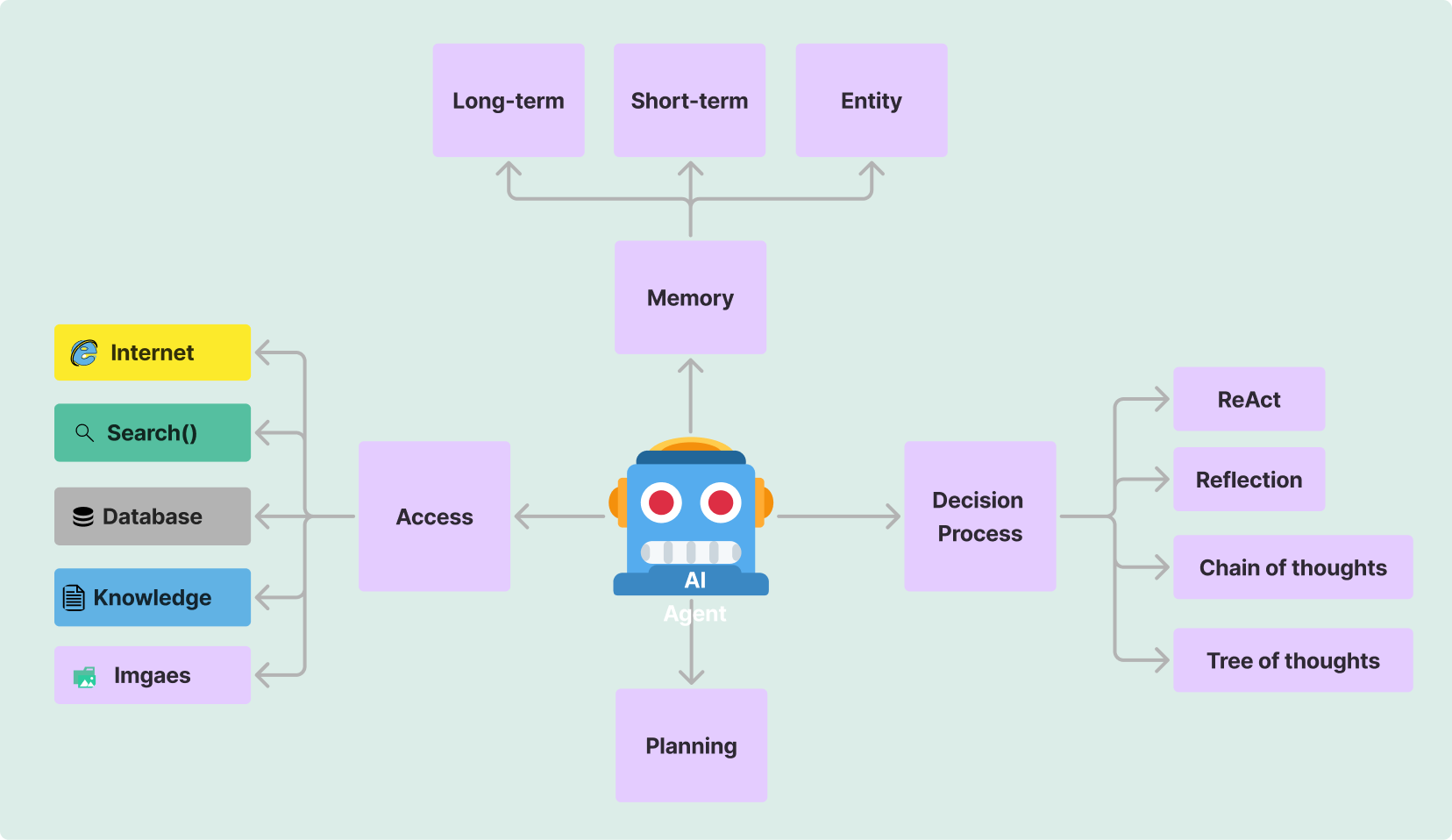
In this post, I'll guide you through implementing a Retrieval Augmented Generation (RAG) system using modern tools and techniques. We'll explore how to combine multiple retrieval methods with reranking for more accurate and relevant responses.
In the landscape of search based Retrieval Augmented Generation (RAG), one component stands out as a game-changer: reranking. Let me give you some context. In semantic only retriever baseds RAG system, we pull data from documents that are semantically similar to the user query. The algorithm that we use known as Approximate Nearest Neighbors (ANN) search, which is fast and efficient. However, bacause of the nature of the algorithm, it can sometimes pull irrelevant data.
Becaus eof irrelevant data, the Large Language Models (LLMs) can hallucinate and provide inaccurate responses. This is where reranking comes in.
Think of reranking as a two-step interview process: the initial retrieval is like screening resumes (quick but broad), while reranking is the in-depth interview (thorough but resource-intensive). This approach has become increasingly important as organizations struggle with LLM hallucinations and accuracy issues. By implementing proper reranking, many teams have reported up to 40% improvement in response accuracy.
What is RAG?
In my last blog post about Building a Multi-agent System, I discussed the importance of combining multiple agents to create a more robust conversational system. Retrieval Augmented Generation (RAG) is a technique that enhances Large Language Models (LLMs) by providing them with relevant context from a knowledge base before generating responses. This approach combines the power of:
- Knowledge retrieval systems
- Semantic search
- Document reranking
- Contextual response generation
A RAG system should have the following characteristics:
- Accurate document retrieval
- Context-aware response generation
- Efficient knowledge base management
- Hybrid search capabilities
- Quality control through reranking
Core Components
Modern RAG systems consist of several essential components working together:
1. Embedding Model
The embedding model converts text into dense vector representations for semantic search:
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-en-v1.5")2. Ensemble Retriever
This component combines multiple retrieval methods for better coverage:
ensemble_retriever = EnsembleRetriever(
retrievers=[semantic_retriever, bm25_retriever],
weights=[0.7, 0.3] # 70% semantic, 30% keyword importance
)3. Document Reranker
The reranker fine-tunes the retrieved documents for maximum relevance:
reranker = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')Implementation Steps
Let's break down the implementation into manageable steps:
- Setting Up the Foundation
# Initialize embedding model and LLM
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-en-v1.5")
rag_llm = ChatGroq(model="llama3-8b-8192")
# Load vector store
vectorstore = Chroma(
collection_name=collection_name,
embedding_function=embed_model,
persist_directory=persist_directory
)- Implementing the Retrieval System
# Create BM25 retriever
bm25_retriever = BM25Retriever.from_texts(all_docs)
# Set up semantic retriever
semantic_retriever = vectorstore.as_retriever(
search_kwargs={"k": 10}
)
# Combine retrievers
ensemble_retriever = EnsembleRetriever(
retrievers=[semantic_retriever, bm25_retriever],
weights=[0.7, 0.3]
)[Previous sections remain the same until the Document Reranker section]
3. Document Reranker
The reranker serves as a crucial refinement layer in modern RAG systems, using cross-encoders to perform deep bi-directional attention between queries and documents. While powerful, reranking comes with important trade-offs to consider:
Advantages:
- Higher Accuracy: Cross-encoders typically achieve 5-10% higher accuracy compared to bi-encoders or BM25 alone
- Better Context Understanding: Deep cross-attention allows for nuanced understanding of query-document relationships
- Reduced Hallucinations: More accurate context selection leads to fewer LLM hallucinations
- Handle Complex Queries: Particularly effective with long or complex questions that require deeper semantic understanding
Disadvantages:
- Computational Overhead: Cross-encoders are significantly slower than bi-encoders or keyword search
- Resource Intensive: Requires more GPU memory due to cross-attention mechanisms
- Scalability Challenges: Processing time increases linearly with the number of documents
- Cost Considerations: Higher computational requirements translate to increased infrastructure costs
Here's how we implement reranking in our system:
reranker = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
async def rerank_documents(query: str, docs: List[Document], k_final: int = 3):
"""
Rerank documents using cross-encoder with performance optimization
Args:
query: User question
docs: List of retrieved documents
k_final: Number of documents to return after reranking
"""
# Batch process documents for efficiency
batch_size = 32
pairs = [(query, doc.page_content) for doc in docs]
# Get scores from re-ranker
scores = []
for i in range(0, len(pairs), batch_size):
batch = pairs[i:i + batch_size]
batch_scores = reranker.predict(batch)
scores.extend(batch_scores)
# Sort documents by score
scored_docs = list(zip(docs, scores))
scored_docs.sort(key=lambda x: x[1], reverse=True)
# Return top k documents
return [doc for doc, _ in scored_docs[:k_final]]Best Practices for Reranking:
- Strategic Placement: Apply reranking after initial retrieval to a smaller document set
- Batch Processing: Implement batching for better throughput
- Careful Tuning: Adjust k_final based on your application's accuracy vs. speed requirements
- Monitoring: Track reranking scores to identify potential issues or biases
A typical optimization approach is to retrieve more documents initially (e.g., top 10-20) and then rerank to select the best 3-5 documents for the final context. This balances the trade-off between accuracy and performance:
# Example optimization workflow
initial_docs = await ensemble_retriever.ainvoke(question) # Get top 10-20 docs
reranked_docs = await rerank_documents(
query=question,
docs=initial_docs,
k_final=3 # Only keep top 3 after reranking
)Best Practices
Query Processing
- Use ensemble retrieval for better coverage
- Implement proper reranking for accuracy
- Format context appropriately for the LLM
Response Generation
- Provide clear system prompts
- Include relevant context only
- Handle edge cases gracefully
Performance Optimization
- Cache frequent queries
- Batch process when possible
- Monitor and log system performance
Future Considerations
As RAG systems continue to evolve, several key areas will shape their development:
Emerging Trends
Advanced Retrieval Methods
- Multi-modal retrieval
- Hierarchical search
- Dynamic context windows
Enhanced Context Processing
- Context compression
- Dynamic context selection
- Relevance scoring
Improved Response Generation
- Few-shot learning
- Chain-of-thought reasoning
- Self-correction mechanisms
Create Your Own Multi-agent System
We created getassisted.ai for building a seamless multi-agent system. You do not need to write any code. The goal is to create an assistant that helps you learn any niche topics. Whether you're a researcher, developer, or student, our platform offers a powerful environment for exploring the possibilities of multi-agent systems. Here is the link to explore some of the: assistants created by our users.
Conclusion
Building a robust RAG system requires careful consideration of various components and their interactions. By following the structured approach outlined in this article and implementing best practices, you can create effective RAG systems that provide accurate and contextually relevant responses.
Remember that the field of RAG is rapidly evolving, and staying updated with the latest developments and technologies is crucial for creating state-of-the-art systems.